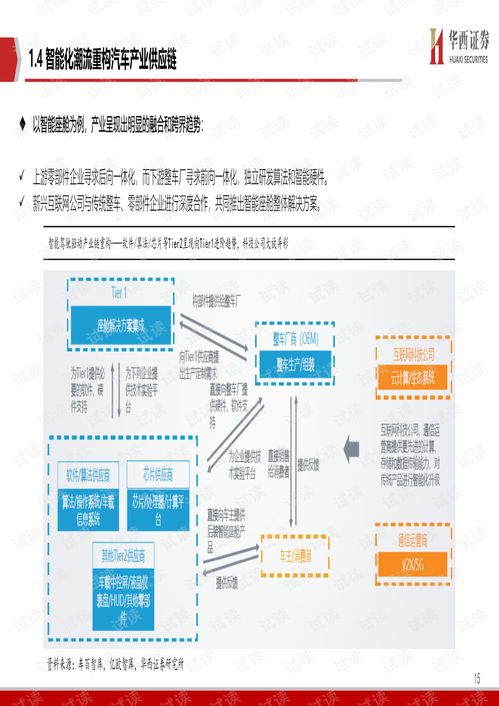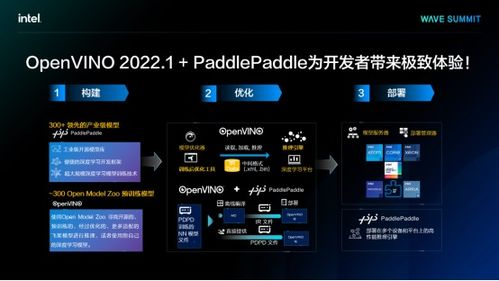
在人工智能技術飛速發展的今天,算力與算法已成為驅動其前進的雙輪。作為全球半導體行業的領軍者,英特爾不僅持續推動硬件算力的邊界,更深刻認識到軟件生態對于釋放硬件潛能、加速AI普惠的關鍵作用。英特爾與百度飛槳(PaddlePaddle)的深度合作,正是“軟硬協同”戰略的典范,旨在從基礎設施層面為人工智能的發展注入強大的“加速度”。
硬件基石:為AI計算提供澎湃動力
英特爾的硬件產品線,特別是至強(Xeon)可擴展處理器,已成為眾多數據中心和AI工作負載的可靠基石。其內置的AI加速技術,如英特爾? 高級矢量擴展512(英特爾? AVX-512)以及集成AI加速的英特爾? AMX(高級矩陣擴展),能夠顯著提升深度學習訓練與推理的效率。這些硬件創新旨在處理海量數據與復雜模型,為包括飛槳在內的AI框架提供了強大、通用且高效的算力支持。
軟件優化:釋放每一分硬件潛能
頂尖的硬件需要極致的軟件優化才能發揮全部實力。英特爾與飛槳的合作核心便在于此。雙方團隊進行了深度的協同優化:
- 框架層優化:針對英特爾架構(IA),特別是至強處理器,對飛槳框架的核心算子、計算圖編譯與調度進行了全方位優化,確保計算任務能在英特爾硬件上以最高效的方式執行。
- 庫函數強化:集成并優化了英特爾 oneAPI 深度神經網絡庫(oneDNN),這是一套性能經過極致調優的構建模塊,用于深度學習應用。通過調用 oneDNN,飛槳能夠直接利用英特爾平臺的低層指令集優化,大幅提升卷積、矩陣乘法等關鍵操作的性能。
- 工具鏈賦能:借助英特爾? OpenVINO? 工具套件,可以進一步優化經飛槳訓練出的模型,并將其高效部署在從邊緣到云端的各種英特爾硬件上,實現跨平臺的高性能推理。
“軟硬一體”的加速度價值
這種“軟硬件雙管齊下”的策略,為開發者與最終用戶帶來了切實的“加速度”:
- 性能顯著提升:經過聯合優化的飛槳在英特爾硬件上運行AI模型,相比未優化版本可獲得顯著的性能提升,意味著更短的訓練時間和更高的推理吞吐量,直接降低了時間與計算成本。
- 開發體驗簡化:開發者無需深入了解底層硬件細節,即可通過熟悉的飛槳API,自動享受到針對英特爾架構的優化好處,從而更專注于算法與模型創新本身。
- 生態兼容與拓展:此舉強化了飛槳在x86生態中的競爭力,也為英特爾龐大的硬件用戶群提供了更優的AI框架選擇,促進了開放、多元AI生態的繁榮。
- 賦能產業智能化:從智慧城市、智能制造到科學發現,性能與效率的提升使得更復雜、更精準的AI模型能夠應用于更廣泛的產業場景,加速千行百業的智能化轉型進程。
共筑開放AI基礎設施
英特爾與飛槳的合作,超越了簡單的技術適配,是構建下一代人工智能基礎軟件棧的重要實踐。它昭示著,在AI時代,真正的“加速度”源于硬件創新與軟件優化的深度融合。通過攜手打造更強大、更開放、更易用的底層基礎,雙方正共同為全球AI開發者與產業界夯實基石,驅動人工智能技術以更快的速度、更低的門檻滲透到社會的每一個角落,共創智能未來。